
Gal Vered - Checksum.ai
The gap AI left open: Writing code is solved. Verifying it is not.




Gal Vered’s team uses Claude Code every day. They also think Claude Code is unreliable. That is not a contradiction. For the co-founder and CEO of Checksum.ai, it is the clearest possible proof of concept.
“We use Claude Code at Checksum and it is very buggy. It's very clear that AI helps you move much faster, but at the same time, it's just one part of the puzzle.”
AI coding tools have largely solved the problem of writing software. They have not touched the harder problem: knowing whether that software actually works. The faster code gets written, the wider that gap grows. Gal and Checksum are building the infrastructure to close it.
The Engineer Who Couldn’t Unsee the Cost
Before Checksum, Gal spent time as a Product Leader at Google, where he got a close look at what serious testing infrastructure actually requires. The experience stuck with him, though not only for the reasons you might expect.
“We rarely broke production,” he says. “Every release went through hundreds of tests first, then thousands in production, slow releases comparing beta users and production users, automatic rollbacks.” The coverage was thorough and the results spoke for themselves. But the price was steep. “It took full teams. The time when an engineer told me the feature is done and I could demo it, till the time we could actually release it, there was a very long period of time.”
For Gal, that experience drew a straight line to what Checksum is building today.
“That kind of showed me the power of having really great coverage, but at the same time how costly it is. Automating with AI becomes the no brainer.”
Verification Is the Bottleneck
The problem, as Gal frames it, is one of pipelines and bottlenecks. When a developer spent three weeks writing a feature, a day or two of testing was a reasonable trade. But when Claude Code compresses that same feature down to an hour or two, testing becomes the thing that slows everything down.
“When you have all of those moving parts just move much faster, so you don’t release one feature a week, you release 100 features a week, it’s just you increase the chance of something breaking exponentially.”
Checksum’s answer to that problem is a simulation engine. “We call it the Code World Model,” Gal says. “It’s basically a model that is able to simulate how software behaves in the world.” Traditional testing tools still operate on the assumption that a human wrote the code carefully and deliberately. Checksum is built for a world where that assumption no longer holds.
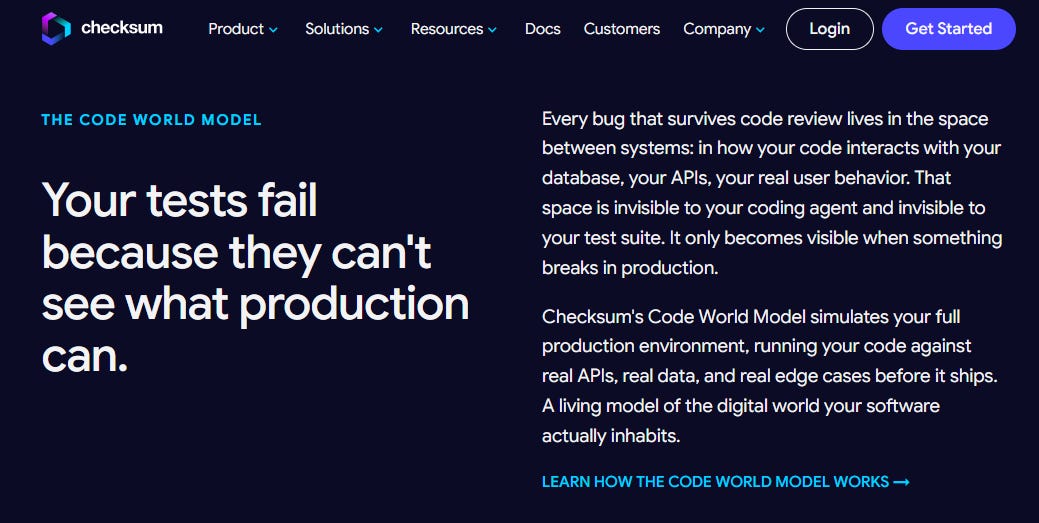
Where LLMs End and the Code World Model Begins
Nearly every company building in this space is putting large language models at the center of their stack. Gal made a deliberate choice not to. “The core part of Checksum is not LLM based. We think this problem is not solvable with large language models.”
That does not mean Checksum avoids them. The company uses LLMs strategically, in targeted moments where they add clear value.
“We use LLMs strategically in order to update the simulation, update the results, determine if the change in behavior is a bug or not. That’s where LLMs are great. It’s high reasoning on small context.”
The simulation engine does the heavy lifting, then hands a focused slice of context to an LLM for the final call.
The philosophy is specific. “Anything you can do with code, you should do with code,” Gal says. “LLMs should be used as little as possible because they’re expensive, not deterministic. And they should only be used for reasoning.” That constraint becomes critical at the scale Checksum operates.
“LLMs today have an effective context window of around 200k tokens. Above that, they become really inaccurate. To solve our problem, even 20 million tokens is not enough. We are simulating terabytes of data.”
The problem compounds when you factor in what LLMs simply cannot access. When Claude Code runs on millions of different machines, each with unique infrastructure, internet connections, and software configurations, no model can parse that context reliably.
“LLMs have no access to this information, and even if you do provide access via API or MCP, they have no ability to actually parse all of this information, because large language models are very good at high reasoning over small amounts of data.”
The Code World Model is built to handle what sits beyond that ceiling: simulating the full complexity of how software actually behaves in production. LLMs have a role in the system. They are just not the center of it.
The Build-It-Yourself Test
The most common objection Checksum faces in the market is also the most predictable one. If Claude Code can write code, why can’t it just write the tests too? Gal’s response is to encourage it. “We encourage people, you should do that,” he says. “And if it solves your problem and you no longer have bugs in production and you can ship fast, then great, you don’t need Checksum.”
“We’re a startup, we are growing fast, we see high demand, we want to find customers that long-term see the value.”
That confidence comes with a clear-eyed prediction about what happens next. “For the most part, people do that and then they realize they have a lot of tests that just test what the code does instead of testing what production will look like and finding bugs. And those tests are very brittle, so they tend to fail and you need to fix them.”
The distinction Gal draws is between two different kinds of tests. Tests written by Claude Code tend to verify that the code behaves exactly as it was written. They confirm the logic is internally consistent. What they do not do is tell you whether that code will hold up against real production conditions: live infrastructure, actual user behavior, and the edge cases that only show up once software is in the wild. That second problem is what Checksum’s simulation is built to solve.
The Moat That Updates Itself
The Code World Model is not a static snapshot of how a company’s software behaves. It is a continuously updated simulation, and keeping it current is one of the harder technical problems Checksum has had to solve. “How do you constantly update the simulation environment?” Gal asks. “Because the goal of a PR is to make a change, and often the PR will change how your software behaves. So how do we update the simulation to match the new request, and how do we decide if a change in behavior is intended or unintended?”
The scope of what the simulation tracks is broad.
“We simulate services, queues, SKUs, millions of distributed systems all working together, all of the different edge cases, network traffic issues, packet loss, migrations, databases, all of the things that really go on in order to make sure your changes are fully working.”
That context, built up over time against a specific company's production environment, is what makes the simulation compound. Every new pull request updates it. Every simulation run adds to it. The result is a picture of how a specific company's software behaves in production that becomes more precise the longer Checksum is in place.
Building for the Agent in the Loop
Checksum produces detailed reports on every simulation run. Most of them are, by design, structured for Claude Code to consume rather than for a human to read directly. “All of our reports are unreadable beyond the high-level summary,” Gal says. “I don’t think I’ve ever seen anyone try to read those reports not through Claude Code.” This is a deliberate architectural decision. The primary consumer of Checksum’s detailed output is Claude Code, which processes the results and feeds them back into the development cycle.
That same logic shapes how Gal thinks about the engineers on his own team. AI tools do not flatten the gap between strong and average engineers. They widen it.
“High agency 10x engineers will be 10x engineers whether they’re junior or senior. The ones who aren’t high agency, you can probably just use Claude Code and get 90% of the output. The people who are high agency take the regular 10x output and are multiplied by another 10x with AI.”
The implication for hiring is practical. Gal’s view is that judgment about what to build matters more now, not less. “The ability to understand the customer and the most impactful next thing to build,” he says, “is where engineering always was the bigger alpha.” Claude Code raises the output ceiling for engineers who already have that judgment. For those who do not, it mostly accelerates the wrong work.
The Case for Continuous Quality
Gal frames what Checksum is building as the next layer of the modern engineering pipeline. CI/CD, continuous integration and continuous delivery, became standard practice because it solved a real problem at scale. Gal sees continuous quality, or CQ, following the same path.
“We think about it as a continuous quality movement, similar to CI/CD. Now there’s CQ. Everything that engineers are doing related to quality, 24/7, automating it with the Code World Model and the simulations and the tests being a central part of it.”
The urgency behind that thesis comes from a simple observation. As AI tools push more code into production faster, the stability of software becomes a purchasing decision, not just an engineering one. Gal points to his own behavior as an example. Between two competing AI assistant tools, Hermes and OpenClaw, he uses Hermes for one reason. “I need something reliable. I need something that works. I don’t have time to debug stuff.” That preference, formed through daily use, reflects a broader shift he sees coming.
“I do think stability will start to become the moat as companies ship more and more code into production.”
For engineering leaders building their stacks today, Gal’s view is that quality infrastructure is not a cost center to be deferred. It is the thing that determines whether faster code delivery becomes a competitive advantage or a liability.
More from Uncovered Media





 | A guest post by
|